octubre 10, 2025
~ 9 MIN
Explore EOTDL through different use cases 📊
use cases
tutorials
Explore EOTDL through different use cases
In this post we present multiple use cases developed with EOTDL so you can get an idea of how to use EOTDL for your own projects:
- Unsupervised Learning: Learn how to create a large dataset for unsupervised pre-training of AI models on Satellogic, Sentinel 2 and Sentinel 1 data, including training code.
- Superresolution: Learn how to create a dataset and train a superresolution model on Satellogic and Sentinel 2 data.
- Multi-task Learning: Learn how to create a dataset and train individual models for image classification, segmentation and on model that performs both tasks at the same time (multi-task learning).
- Road Extraction: Learn how to create a dataset and train a road extraction model on Sentinel 2 data, based on an exsiting dataset of road labels.
Throughout these use cases we share datasets and models ready to use as well as pipelines that you can leverage to reproduce the results or as starting point for your own projects.
You can find the source code for all the use cases in the EOTDL GitHub repository.
Unsupervised Learning
Unsupervised learning is a type of machine learning where algorithms learn patterns directly from unlabeled data, without any explicit annotations or human-provided categories. Unlike supervised learning—which relies on labeled datasets to learn a mapping from inputs to outputs—unsupervised learning tries to discover the underlying structure, clusters, or features within the data itself.
This approach is particularly valuable for image analysis and, especially, for satellite imagery. Satellite datasets are immense and diverse, often containing millions of images covering varied geographies and timeframes. However, manually annotating or labeling every image in such datasets is typically infeasible due to the sheer scale and specialist knowledge required.
A core outcome of unsupervised learning on images is the ability to train models that generate embeddings—compact vector representations—that capture essential features and patterns within the data. When a model (such as a convolutional neural network or transformer) is trained unsupervised, it learns to encode key aspects of images (like texture, shape, or context) into these embeddings without needing any labels.
Unsupervised learning is the core technology behind foundation models, which are large-scale models that are trained on a large amount of data to learn general features and patterns that can be used for a wide range of tasks. Some examples of foundation models are:
- Prithvi (Earth Observation Foundation Model by IBM)
- CLAY (Climate Learning and Analysis foundation model)
- Google AlphaEarth
Our use case leverages EOTDL to:
- Generate a large dataset formed of Satellogic and matching Sentinel 2 and Sentinel 1 images. These dataset can be used to train an unsupervised model for downstream tasks with the different modalities or individual models for each modality.
- Train unsupervised models for each modality using the Barlow Twins method.
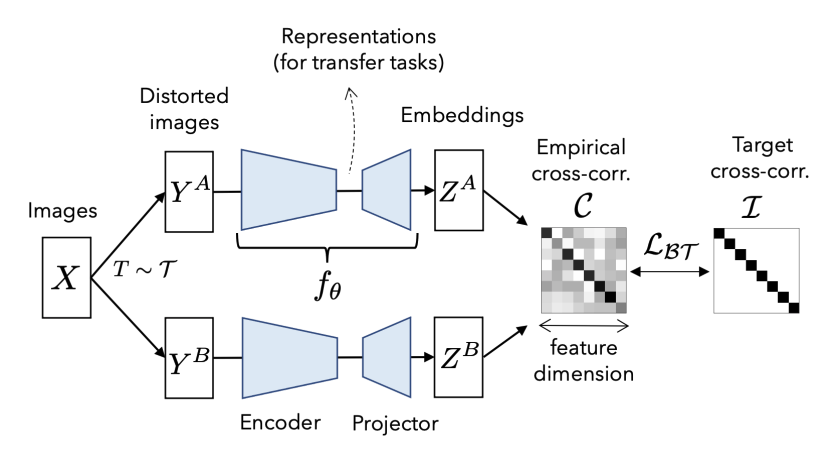
The following resources are available to you:
- Ready to use pipeline to generate the dataset, train and evaluate the models.
- Metadata for the Satellogic dataset and 1M pre-computed Sentinel 2 and Sentinel 1 matches at https://www.eotdl.com/datasets/SatellogicDataset (you can download the images following the instructions in the pipeline).
- Pre-trained Models.
- Full code for the use case in the EOTDL GitHub repository.
Superresolution
Superresolution is a technique that allows to artificially increase the resolution of an image. This is particularly useful for satellite imagery, where the resolution is often low (10m, 20m, 30m, etc.). Increasing the resolution by 2x, 3x or even 4x can help improve the performance of downstream tasks such as classification, segmentation and object detection.
This is particularly useful when models have been trained on high resolution images where annotations can be made with confidence, but not on low resolution images where annotations are more difficult to make. These models can then be fed with superresolved low resolution images to improve their performance. However, the transferability of the model is not always guaranteed and it is important to evaluate the performance of the model on the low resolution images.

This use case leverages EOTDL to:
- Generate a large dataset formed of Satellogic and matching Sentinel 2 images. This dataset can be used to train superresolution models.
- Train a superresolution model using the ESRT model.
The following resources are available to you:
- Ready to use pipeline to generate the dataset, train and evaluate the models.
- Metadata for the Satellogic dataset and 1M pre-computed Sentinel 2 matches at https://www.eotdl.com/datasets/SatellogicDataset (you can download the images following the instructions in the pipeline).
- Pre-trained Models.
- Full code for the use case in the EOTDL GitHub repository.
Multi-task Learning
Multi-task learning is a technique that allows to train a single model to perform multiple tasks at the same time.
Traditionally, ML and AI models have been trained to perform a single task at a time. In Earth Observation, this can be for example scene classification, object detection, semantic segmentation, etc. In this setup, a dataset of images with the corresponding labels for the particular task is required. If we want to tackle a different task, then a new datasets has to be created and a new model has to be trained. While this process has led to good results, it is not always the most efficient way to tackle the problem.
On the other hand, multi-task learning allows to train a single model to perform multiple tasks at the same time. For this method to work, our dataset must include the corresponding labels for the different tasks given a single inputs. This means, for each satellite image, we must have the corresponding labels for classification, segmentation, object detection, etc.
Multi-task learning has the potential to be more efficient than training separate models for each task:
- A single model can be trained faster than multiple models (even if the single model is larger or is trained with more data, it can be trained in less time than the rest of the models combined).
- A single model simplifies deployment and maintenance, as it requires less infrastructure and less resources to maintain.
- A single model can outperform multiple specialized models in some cases since it can leverage the different tasks to improve the performance of the model.
Multi-task learning is specially used in autonomous driving, where a single model is responsible for producing hundreds of different outputs at the same time from a single input image.
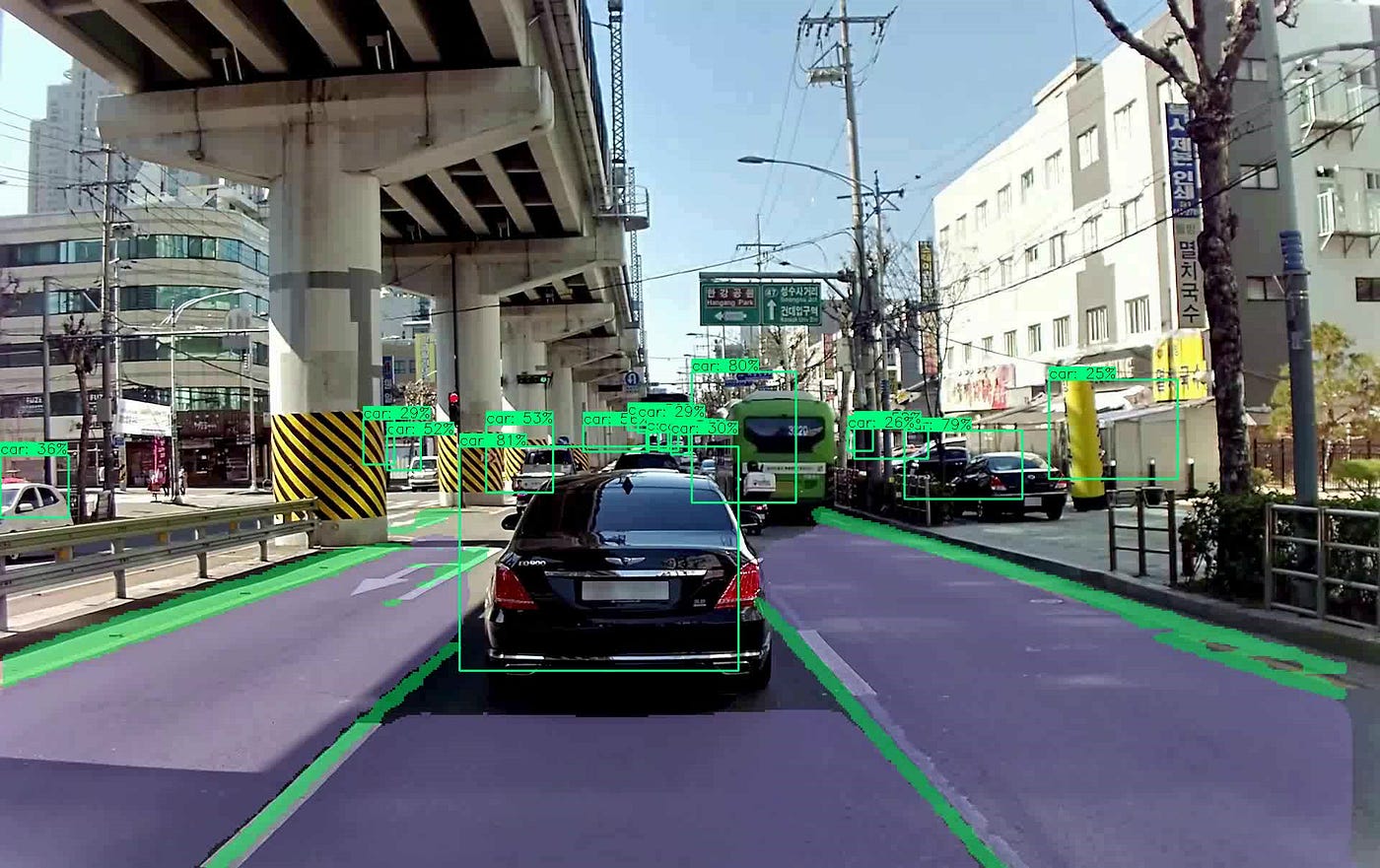
In our use case, we leverage EOTDL to:
- Generate a small dataset of Satellogic images.
- Use the SCANEO labelling tool to label the images for classification and segmentation, since no labels are available for the given source images.
- Train, evaluate and compare the performance of individual and multi-task models.
- Leverage the trained models to label more data with SCANEO taking advantage of the assisted labelling capabilities. To do so, an inference API is provided to perform inference on the models and retrieve the outputs in the labelling tool (which can be edited and validated). This enables Active Learning, where the model is used to label the data and the model is then updated with the new data, improving both the model and dataset in iterative cycles.
The following resources are available to you:
- Ready to use pipeline to generate the dataset, train and evaluate the models.
- Metadata for the Satellogic dataset at https://www.eotdl.com/datasets/SatellogicDataset (you can download the images following the instructions in the pipeline).
- SCANEO labelling tool https://github.com/earthpulse/scaneo.
- Pre-trained Models.
- Full code for the use case in the EOTDL GitHub repository.
Active Learning is a technique that allows to train a model with less data by iteratively selecting the most informative examples to label. This is particularly useful when the labelling process is expensive or time consuming. SCANEO and EOTDL provide tools to enable Active Learning, so you can build your own Active Learning pipeline to train your models and generate datasets in an iterative and efficient way.
Use EOTDL to gather and prepare data, leverage SCANEO to label the data. Then, come back to EOTDL to train the model. Start an inference API to connect the trained model with SCANEO and label more data. Through this process, you can focus on the annotations that your model needs to improve, rather than spending time on gathering and preparing data. Re-train the model with the new data and repeat the process until you meet your target performance.
This use case provides an example to kickstart your own Active Learning pipeline.
Road Extraction
Road extraction is a technique that allows to extract the roads from a satellite image. This is particularly useful for urban planning, disaster management, and transportation networks.

Several dataasets exist for road extraction, such as the Massachusetts Roads Dataset or the Deep Globe Road Extraction dataset. However, these datasets are based on high resolution images, often extracted from available open maps, and not globally distributed which harms the performance of road extraction in some parts of the world.
Our goal with this use case is to train a road extraction model on Sentinel 2 images that performs well all over the world, enabling applications such as traffic monitoring, disaster management, and transportation networks in developing countries.
This use case leverages EOTDL to:
- Generate a dataset of Sentinel 2 images with road labels extracted from another dataset, so we need to find matching Sentinel 2 images for the given bounding boxes.
- Train a road extraction model.
The following resources are available to you:
- Ready to use pipeline to generate the dataset, train and evaluate the models.
- Ready to use datasets for road extraction from Sentinel 2 and High Resolution images.
- Pre-trained models for road extraction with Sentinel 2 and High Resolution images.
- Full code for the use case in the EOTDL GitHub repository.